מאת: יעל הלפמן כהן
"אנחנו הולכים הכי אחורה, לטבע, בשביל לפתור בעיה הכי מודרנית שיש", מספר עומר צברי, דוקטורנט בפקולטה למדעי המחשב, במעבדה של פרופ' איתן יעקובי, כשהוא מתאר מה הוא עושה.
הבעיה המודרנית היא התפוצצות של דאטה. כמות המידע בעולם הולכת וגדלה בקצב אדיר, ואת המידע הזה צריך לאחסן איפשהו. רק כדי להבין את המימדים, ההערכה היא שעד סוף השנה כמות המידע לאחסון תהיה שקולה לכמות הידע המאוחסנת ב-360 מיליארד לפטופים!
רוב המידע הזה הוא מידע קר, כלומר מידע שכמעט ולא ניגשים אליו, אך עדיין יש צורך לשמר אותו. התחזוקה כמובן צורכת חשמל רב. למשל כיום, 5% מצריכת החשמל בארה"ב וזה עתיד לעלות ל- 8%, מיועדת לאחסון מידע. מדובר במפגע אנרגטי שמצריך פתרון בהול.
ללכת הכי אחורה, לטבע, זה לחזור למערכת אחסון המידע היעילה ביותר בטבע, ה- DNA.
ה DNA הוא מערכת אחסון מידע אולטימטיבית – עמידה, קומפקטית, וניתנת לשכפול. המידע הגנטי נרשם ב- DNA לאורך שנים והוא יציב לאורך זמן. כמה יציב? יש סיפורים של שחזור חיים קדמונים גם אחרי מיליוני שנים משרידי DNA.
הפתרון המתבקש הוא לאחסן את המידע בכוננים ביולוגים. ה- DNA יכול לדחוס פי 10 בשמינית מכל הארד דיסק! הרעיון של אחסון מידע ב-DNA אינו חדש, ריצארד פיינמן, זוכה פרס נובל לפיסיקה, העלה רעיון זה בשנת 1959, אך הניסוי הראשון שבו נשמרה כמות משמעותית של מידע למעשה בוצע רק ב-2012, עם הבשלת הטכנולוגיה.
אחסון מידע ב DNA הוא תחום פורץ דרך שמשתמש במולקולות ה-DNA כדי לאחסן נתונים דיגיטליים באופן קומפקטי ועמיד לאורך זמן. הרעיון מבוסס על כך שניתן לקודד כל מידע, שבדרך כלל מיוצג במחשבים בצורה בינארית (‘0’ ו-‘1’) לכדי רצפי DNA אשר מורכבים מארבעה בסיסים חנקניים (A, C, G, T). על בסיס הרצפים המקודדים האלו, ניתן לסנטז מולקולות DNA סינטטיות (oligonucleotides), אשר בעת הצורך אפשר לרצף ולפענח וכך לקרוא את המידע. הקידוד והאלגוריתמים לפענוח המידע מוסיפים יתירות מסויימת אשר מבטיחה כי המידע ייקרא באופן שלם גם בהינתן שגיאות במהלך ייצור, אחסון, וקריאת ה-DNA.
היתרונות של אחסון מידע ב-DNA בולטים: צפיפות אחסון עצומה ועמידות המידע לטווח ארוך. הפועל היוצא- חיסכון אנרגטי.
החזון של עומר ואיתן, הוא לתת פתרון לארכיונים של מידע, בעלות אנרגטית נמוכה משמעותית. חברות כמו BioMemory ו- Twist Bioscience כבר מפתחות מערכות מבוססות DNA לאחסון מידע, והתחום צפוי להתקדם משמעותית בעשורים הקרובים ,אך הטכנולוגיה עוד לא הבשילה לכדי מוצר בשוק.
איך זה עובד?
קידוד הנתונים – מידע דיגיטלי (קובץ, תמונה, טקסט) מומר לרצפים של A, T, C, G.
סינתזה של DNA – מייצרים כימית את הרצפים במעבדה בהתאם לקוד.
אחסון פיזי – ה DNA נשמר בתוך מבחנה או בתנאים יבשים וקרירים.
שליפה ושחזור – כשצריך לגשת למידע, עושים ריצוף (קריאה) של ה-DNA- ממירים חזרה לקובץ דיגיטלי, ומשחזרים את הנתונים.
האתגרים הפתוחים שנשאר לפתור עבור בנייה של כונני אחסון מבוססי DNA כוללים את צוואר הבקבוק של סינתזת ה-DNA, אשר מזוהה כיום כחסם עקב העלות הגבוהה של התהליך יחסית לפתרונות אחסון אחרים בשוק. חסם נוסף הוא טיפול בשגיאות בקריאה ובכתיבה עקב מוטציות טבעיות ושגיאות הסרה והוספה (Insertion/Deletion). הפתרון במקרה זה הוא הטמעת מנגנונים לתיקון שגיאות כבר בעת קידוד המידע. הרבה מאתגרי הקידוד, אחזור המידע ותיקון השגיאות נפתרו במסגרת עבודת הדוקטורט של עומר.
הידיעה נכתבה בעקבות ראיון עם עומר צברי.
תיאור סכמטי של מערכת אחסון מידע מבוססת DNA:
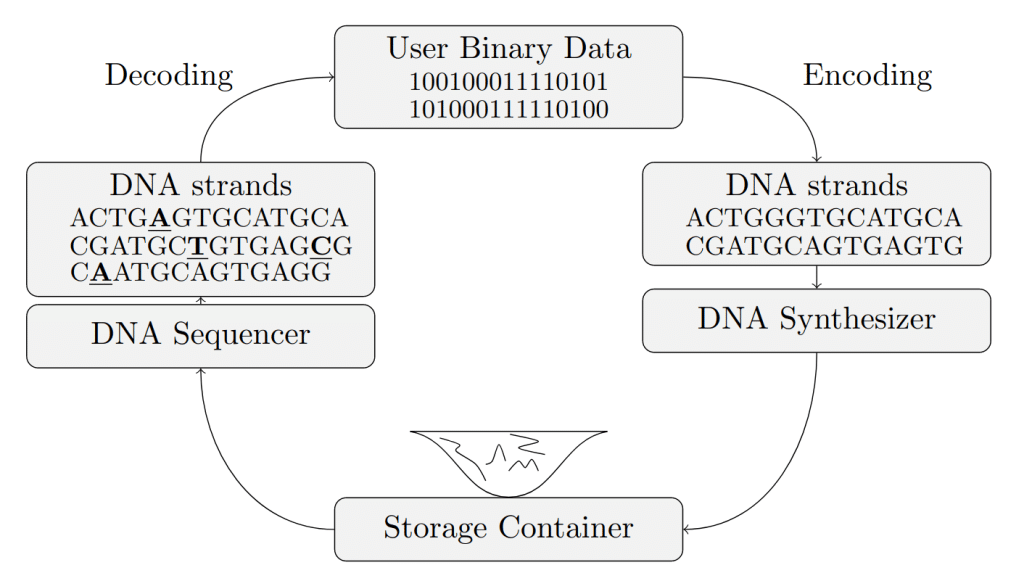
תרשים מאת איתן יעקובי ואנדראס לנץ.
